We’ve got a lot of great work to report on - all projects funded in Q1 2024. Thanks to all!
clojure-lsp: Eric Dallo
Instaparse: Mark Engelberg
Jank: Jeaye Wilkerson
Scicloj: Daniel Slutsky
SiteFox: Chris McCormick
UnifyBio: Benjamin Kamphaus
Wolframite: Thomas Clark
clojure-lsp: Eric Dallo
Q1 2024 Funding. Reports 2 & 3. Published March 1 and April 1, 2024
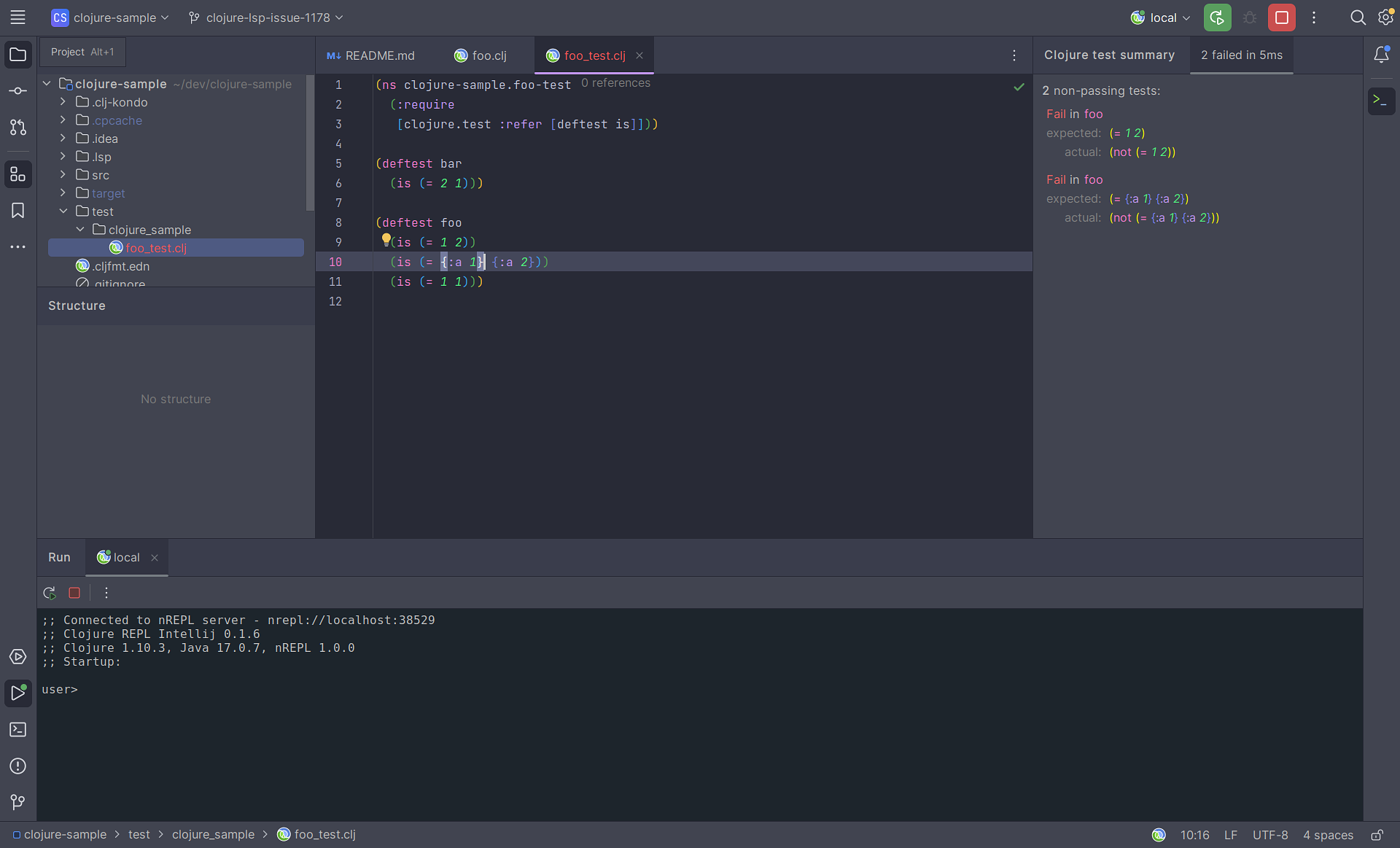
The main highlight from my work in February is the new linter different-aliases helps guarantee consistency across alias in your codebase!

In April I spent some time fixing and improving clojure-lsp for Calva, but most of the time working on the IntelliJ support for LSP and REPL, improving both clojure-lsp-intellij and clojure-repl-intellij.
2024.03.01-11.37.51
General
- Bump clj-kondo to
2024.02.13-20240228.191822-15.
- Add
:clojure-lsp/different-aliases linter. #1770
- Fix unused-public-var false positives for definterface methods. #1762
- Fix rename of records when usage is using an alias. #1756
Editor
- Fix documentation resolve not working for clients without hover markdown support.
- Added setting to allow requires and imports to be added within the current comment form during code action and completion:
:add-missing :add-to-rcf #1316
- Fix
suppress-diagnostics not working on top-level forms when preceded by comment. #1678
- Fix add missing import feature on some corner cases for java imports. #1754
- Fix semantic tokens and other analysis not being applied for project files at root. #1759
- Add support for adding missing requires and completion results referring to JS libraries which already have an alias in the project #1587
2024.03.31-19.10.13
Editor
- Adding require command fails for requires without alias. #1791
- Add require command without alias now add requires with brackets.
- Project tree feature now support keyword definitions like re-frame sub/reg.#1789
- Support
textDocument/foldingRange LSP feature. #1602
- Improve
textDocument/documentSymbol considering keyword definitions and returning flatten elements.
- Fix Add require/import usages count in code actions. #1794.
2024.03.13-13.11.00
General
- Bump clj-kondo to
2024.03.13 fixing high memory usage issue.
Editor
- Fix
workspace/didChangeConfiguration exception causing noise on logs. #1784
1.14.8 - 1.14.10
- Fix exception when starting server related to previous version.
- Fix some exceptions that can rarely occurr after startup.
- Bump clojure-lsp to
2024.02.01-11.01.59.
There was a major change to how the plugin starts clojure-lsp, now it starts a clojure-lsp process under the hood (like all other editors) instead of using clojure-lsp as a JVM deps, this fixed a lot of macos bugs.
Also this adds support for “find implementations” of defmultis and protocols, something that it was never possible in any other IntelliJ plugin.
2.0.0 - 2.3.2
- Use clojure-lsp externally instead of built-in since causes PATH issues sometimes. Fixes #25 and #26
- Fix multiple code lens for the same line. #29
- Fix os type for macos non aarch64 when downloading clojure-lsp server.
- Fix references for different URIs when finding references.
- Fix only noisy codelens exception. #33
- Support “Find implementations” of defmultis/defprotocols. #31
- Fix commands, code actions not being applied after 2.0.0.
- Improve “find declaration or usages” to show popup for references.
- Improve Find references/implementations to go directly to the usage if only one is found. #39
- Wait to check for client initialized to minor cpu usage improvmenet.
- Support multiple projects opened with the plugin. #37
- Fix Stackoverflow exception when renaming. #32
- Add common shortcuts to DragForward and DragBackward.
- Fix race condition NPE when intellij starts slowly.
Although this is not related with clojure-lsp, it’s a critical library for IntelliJ usage since without it, there is no REPL usage using only LSP.
I spent considerable time adding the missing feature to make this plugin good enough for a stable release.
Now the plugin has test support!
0.1.7 - master
- Use cider-nrepl middleware to support more features.
- Add test support. #46
- Fix freeze on evaluation. #48
- Improve success test report message UI.
- Support multiple opened projects. #51
- Fix eval not using same session as load-file. #52
Instaparse: Mark Engelberg
Q1 2024 Funding. Report 1. Published March 30, 2024.
Thanks to funding from Clojurists Together, I have been able to review Instaparse pull requests that have been submitted over the past couple of years. I began by incorporating some “low-hanging fruit” pull requests, which addressed some quality-of-life issues raised by users with minimal changes to the code. Although these were small changes and code was contributed by other users, I needed to test the code and make sure the changes were adequately documented.
I also engaged with users who submitted issues where I needed more explanation or input to carefully consider their proposals. In some cases, I spent time evaluating pull requests but eventually decided not to incorporate that pull request. A good example of this was tonsky’s proposal to change the way that parsers and error messages print at the REPL. His proposal was logical but would be a breaking change, which posed a dilemma. After collecting information from him, I consulted with other Clojurists who are involved with instaparse as well as pretty printing and REPLs. I came to the conclusion that it was better to leave as-is.
The most interesting issue I began looking at was a suggestion to incorporate namespaced non-terminals. This is an excellent suggestion because namespaced keywords have taken on much more importance in Clojure since the time instaparse was initially released, due to their critical role in Datomic and Spec. This will be my next area of focus.
I had hoped to complete more work on namespaced keywords, but I spent most of March ill with covid (my first time getting covid), which delayed my work on this more substantive issue. So, rather than wait for the completion of that work, I deployed a new release with the pull requests I had incorporated so far (actually two releases in quick succession: 1.4.13 and 1.4.14) and I look forward to making progress on namespaced keywords in the coming weeks.
Jank: Jeaye Wilkerson
Q1 2024 Funding. Report 2. Published March 30, 2024.
Oh, hey folks. I was just wrapping up this macro I was writing. One moment.
(defmacro if-some [bindings then else]
(assert-macro-args (vector? bindings)
"a vector for its binding"
(= 2 (count bindings))
"exactly 2 forms in binding vector")
(let [form (get bindings 0)
pred (get bindings 1)]
`(let [temp# ~pred]
(if (nil? temp#)
~else
(let [~form temp#]
~then)))))
“Does all of that work in jank?" I hear you asking yourself. Yes! Indeed it
does. Since my last update, which added dynamic bindings, meta hints, and initial reader macros, I’ve finished up syntax quoting support, including gensym support, unquoting, and unquote splicing. We might as well see all of this working in jank’s REPL CLI.
❯ jank repl
> (defmacro if-some [bindings then else]
(assert-macro-args (vector? bindings)
"a vector for its binding"
(= 2 (count bindings))
"exactly 2 forms in binding vector")
(let [form (get bindings 0)
pred (get bindings 1)]
`(let [temp# ~pred]
(if (nil? temp#)
~else
(let [~form temp#]
~then)))))
#'clojure.core/if-some
> (if-some [x 123]
(str "some " x)
"none")
"some 123"
> (if-some [x nil]
(str "some " x)
"none")
"none"
>
New interpolation syntax
Some of the early feedback I had for jank’s inline C++ support is that the
interpolation syntax we use is different from what ClojureScript uses. Turns out
there’s no reason to be different, aside from jank needing some more work, so
jank has been improved to support the new ~{} syntax. If you’re not familiar,
inline C++ in jank looks like this:
(defn sleep [ms]
(let [ms (int ms)]
; A special ~{ } syntax can be used from inline C++ to interpolate
; back into jank code.
(native/raw "auto const duration(std::chrono::milliseconds(~{ ms }->data));
std::this_thread::sleep_for(duration);")))
More reader macros
Aside from that, reader macro support has been extended to include shorthand
#() anonymous functions as well as #'v var quoting. The only reader macro
not yet implemented is #"" for regex. All of that concludes what I had aimed
to accomplish for my quarter, and then some. It doesn’t stop there, though.
New logo
I’m wonderfully pleased to announce that jank now has a logo! The logo was
designed by jaide, who was graciously patient
with me and a joy to work with through the various iterations. With this logo,
we’re capturing C++ on one side, Lisp on the other, and yet a
functional core.

Transients
Back to code. In truth, there’s more work going on. A lovely man named
Saket has been helping me fill out jank’s
transient functionality, which now includes array maps, vectors, and sets, as
well as the corresponding clojure.core functions. This is not the first time
I’ve brought up Saket, since he also implemented the initial lein-jank plugin.
Let’s take a look at that.
lein-jank
This plugin isn’t ready for prime time yet, but it’s a good proof of concept
that jank can work with leiningen’s classpaths and it’s a good testing ground
for multi-file projects. jank will be adding AOT compilation soon and this
lein-jank plugin will be the first place new features will land. As a brief
demonstration of where it is today, take a look at this session.
❯ cat project.clj
(defproject findenv "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.11.1"]]
:plugins [[lein-jank "0.0.1-SNAPSHOT"]]
:jank {:main findenv.core})
❯ cat src/findenv/core.jank
(ns findenv.core)
(defn -main [& args]
(let [env-var (first args)
; Call through into native land to look up the var.
env-val (or (native/raw "auto const str(runtime::detail::to_string(~{ env-var }));
__value = make_box(std::getenv(str.c_str()));")
"var not found")]
(println env-val)))
❯ export FINDME="found me!"
❯ lein jank run FINDME
found me!
❯ lein jank run YOUWONTFINDME
var not found
❯ lein jank run LC_ALL
en_US.UTF-8
Migration from Cling to clang-repl
Lastly, I’ve been working on migrating jank to use the upstream LLVM version of
Cling, called clang-repl. The key benefit here is that we’d no longer need to
compile our own Cling/Clang/LLVM stack in order to build jank and we can
distribute jank to use each distro’s normal LLVM package, rather than its own.
On top of that, future work is happening more on clang-repl than on
Cling, so it has recent support for loading pre-compiled C++20 modules, for
example. That would greatly improve jank’s startup performance, since Cling
doesn’t allow us to load pre-compiled modules at this point.
Work here is ongoing and there are some bugs that I have identified in clang-repl
which need to be fixed before jank can fully make the switch. I’ll keep you all updated!
Scicloj: Daniel Slutsky
Q 1 2024 Funding. Report 2. Published March 31, 2024.
March 2024 was the second of three months on the Clojurists Together project titled “Scicloj Community Building and Infrastructure”. Scicloj is an open-source group developing Clojure tools and libraries for data and science.
As a community organizer at Scicloj, my current role is to help make the emerging Scicloj stack easier and more accessible for broad groups of Clojurians. I collaborate with a few Scicloj members on this.
In March 2024, this has been mostly about the following projects. The projects are listed by their proposed priorities for the coming month.
The new real-world-data group is ranked highest for its impact on community growth. This means the following. Assuming this group will (hopefully) grow well and demand attention, the goals of other projects will receive less attention and will be delayed. However, some of them (e.g., required extensions or bugfixes to libraries) will receive more attention if the real-world-data group requires them.
The real-world-data group is a space for Clojure data and science practitioners to bring their data projects, share experiences, and evolve common practices.
March summary
- had quite a few one-on-one meetings with group members, discussing their goals, interests, and needs
- had the first group meeting, including personal introductions, talks by Kyle Passarelli and by Adham Omran, a hands-on part, and discussions
- started creating introductory materials to support the group (see the Scrapbook section)
April goals
- have more one-on-one meetings, two more group meetings, and ad-hoc small topical meetings
- help the participants take on active paths that connect their interests with community goals
The Noj project bundles a few recommended libraries for data and science and adds convenience layers and documentation for using them together.
March summary
- reorganized the docs and clarified the status of different parts
- moved some parts of the experimental functionality to other libraries
April goals
- start stabilizing important parts of the experimental API (noj.vis.*, noj.stats)
- improve documentation
The Clojure Data Scrapbook is intended to be a community-driven collection of tutorials around data and science in Clojure.
March summary
- created a simple contribution guide
- content updates:
April goals
- encourage and help community contributions to the scrapbook
- keep adding content to support other projects
Clay is a minimalistic namespace-as-a-notebook tool for literate programming and data visualization.
March summary
- user support
- bugfixes, extensions, and performance improvements
- 7 minor releases
- shifted from Alpha to Beta stage
April goals
- support user needs, especially in study groups
- explore adding emmy-viewers support
Kindly is a proposed standard for requesting data visualizations in Clojure.
April goals
- discuss Kindly integration with visual tool authors
This group’s goal is to create collaborations in learning and building Clojure tools for data visualization, literate programming, and UI design.
March summary
April goals
- continue the grammar-of-graphics exploration
- have at least one more study session
Cmdstan-clj is a draft library for interop with Stan (probabilistic modeling through Bayesian statistics).
April goals
- practice usage with community members and keep developing by need
Your feedback would help
Scicloj is in transition. On the one hand, quite a few of the core members have been very active recently, developing the emerging stack of libraries. At the same time, new friends are joining, and soon, more people will enjoy the Clojure for common data and science needs.
If you have any thoughts about the current directions, or if you wish to discuss how the evolving platform may fit your needs, please reach out.
SiteFox: Chris McCormick
Q1 2024 Funding. Report 2. Published March 30, 2024.
Hello! The second half of my Clojurists Together funded work on Sitefox is complete. I made around 30 commits to the project for a total of 80 since the start of the year and this is a summary of the progress I’ve made.
My goal with the Clojurists Together funding has been to make it safer and easier for other people to get started building sites and apps on Sitefox. There were two components to this: a) improving documentation and setup tooling; b) improving security and stability.
E2e testing
I continued work on e2e tests for Sitefox. I did this to lay the groundwork for other improvements and get confidence that my changes aren’t breaking any major functionality. I made three main improvements to the tests:
- I started by finshing off the AJAX fetch request test which includes CSRF testing.
- I created a new set of CI rules to run the tests using Postgres, in addition to Sqlite.
- I got basic testing in place against shadow-cljs in dev and compiled release modes.
These tests enabled me to replace the CSRF protection module, make changes to the database layer, and upgrade dependencies knowing the main functions of the framework were still working.
Dependency upgrades
Once I had finished the AJAX request CSRF tests I was able to finish replacing the csurf module. I chose csrf-csrf as the replacement and with a few tweaks I was able to verify it as a drop-in replacement. I also upgraded nbb and the Express webserver module which was flagged by GitHub security infrastructure as vulnerable.
Database layer changes
Sitefox wraps the Keyv key-value database layer and it features functions for filtering data based on the result of a callback. Previously this would load all of the rows of the table into memory before running the filter, but I updated it to do this sequentially in batches instead. I also tweaked the way values are deserialized to use the underlying library’s method, and removed some legacy cruft to do with the way objects were returned. I used the database tests to verify that none of these changes impacted typical database use-cases.
Other misc. updates
Various other updates I made to Sitefox included: adding to the auth layer the ability to dynamically redirect on sign-out, inlining the npm “create” scripts so they are part of the main monorepo, and general code tidying and linter fixes.
Presentations
Near the end of February I gave a talk about Sitefox to the London Clojurians meetup group. This was useful as it helped me distill the core ideas behind Sitefox and get feedback from the community.
Finally, one of my goals was to create a “getting started” tutorial. I wrote the tutorial and shot a simple YouTube video, but then discovered the sound had some issues. I will re-record this video with better sound and upload it, as well as publishing the text version of the tutorial to help people get started with Sitefox.
What’s next
Now that the funding period is complete I intend to continue Sitefox maintenance and updates. I have started by cutting a release (v0.0.19) with all of the changes made during the Q1 2024 Clojurists Together funding period.
One thing I am particularly interested in is building an RPC layer as an alternative to cumbersome REST or GraphQL communications. I hope this will make ClojureScript client-server code more natural to write and reason about without hiding away fundamental information about which computer the code is running on. Hopefully more on that later.
I’m very grateful to have received this support from Clojurists Together. Of course the funding itself is helpful but the most important thing for me was that it showed others are interested in this work and find it valuable and worth working on.
Thanks again for your interest and your support!
UnifyBio: Benjamin Kamphaus
Q1 2024 Funding. Report 2. Published March 31, 2024.
Since the last update, most of my development effort has been split
into three areas:
- Data-driven validations (essentially resulting in specs applied to imported data, as well as other constraints)
- Data lifecycle management (retractions work, but diff/merge still in progress)
- Example dataset for quickstart, and full tutorial (I have tiput together he example, support docs still in progress)
I haven’t completely wrapped these yet as of Mar 31, but I am very close on the first and last bullet. I will try to update Clojurists Together and the larger data sci/engineering and datomic communities when these things are all available.
Some of my time was spent figuring out what a sustainable long-term solution would be for continuing to develop the core of UnifyBio and to ensure it sees actual use in the life sciences. I had some discussions with different orgs and ended up accepting a full-time position at the Rare Cancer
Research Foundation (just started at the end of this quarter), where I’ll have support to further develop UnifyBio. This means the project will probably be moved to the RCRF repo, and there’s a possibility it might be re-branded, or that the UnifyBio name and site might be brought under RCRF’s umbrella. UnifyBio will remain open source, regardless of where it lives. I’ll update Clojurists Together when I have this information, so the project can be pointed to.
IMO this is an ideal place to be positioned coming out of this quarter where I’ve been working on the project as an independent, supported by a mix of client work and funding like the small grant provided to me by Clojurists Together. This change does mean I’ll be spending more time on bio specific applications and not as much work focused on making Unify a generically useful tool for Clojure data science, but this won’t be a 100% shift, as general use will continue to be helpful for the health of the open source data commons ecosystem I’ll be building with RCRF.
I want to thank Clojurists Together again for helping me bridge a time of uncertainty in this interim period while I was working on UnifyBio as a solo dev, and didn’t yet have longer term support from a sponsor or employer.
Wolframite: Thomas Clark
Q1 2024 Funding. Report 1. Published April 15, 2024.
- Overview
- Code organization
- User experience
- Documentation
- Preparation
Overview
Well, 1 and a half months, much confusion and 1 baby later, we have officially sunk our teeth into the wolfram<->clojure bridge. Wolframite, as newly christened by Pawel, is the continuation of Clojuratica: a geat project, pioneered by great people over more than 15 years. As such, the main task for this part of the funding was simply to get to grips with what’s going on underneath before we can prepare it for posterity. A summary of the work so far follows below.
Code organization
A big part of the work was debugging and merging all of the great things that Pawel and others contributed with the current system. As such, main is now up to date and stable. Examples of incorporated work are making sure that we don’t rely on macros or dynamic vars and that options are passed explicitly. The API has been cleaned up, seprating core functionality from tools etc. and functions and namespaces have been renamed to enforce a standard across the codebase.
User experience
For the user, we have particularly worked on the initialization experience. This has involved fixing bugs that prevented the use of wolframengine on linux, type mismatches, reordering engine priorities (Wolfram has different flavours of installation) and having clearer error messages (e.g. when executables and licences are missing). As well as basic streamlining (removing the need for flags etc.), we have ensured a more robust jlink detection, un-lazy interning and significantly faster symbol loading. We have also, with thanks to Daniel Slutsky, integrated support for ’clay’ and the ’kindly’ system, with a plan for allowing users to specify their own clojure<->wolfram aliases.
Documentation
As well as updating the key, user-facing docs, we have also built a series of troubleshooting tips and development documentation that will no doubt grow before (and after) release. This was further complemented with ongoing internal commenting within the source code. Additionally, we have a new demo notebook that illustrates clay and kindly, and two example physics namespaces that demonstrate the bridge for a couple of real-world problems.
Preparation
Finally, an important part of this early stage has simply been the necessary preparation for the second half, where the lion’s share of our contribution is expected to be felt (particularly now that no more deliveries of small people are expected :) ). Such preparation has largely focused on learning and documenting the internal code structure, opening channels with the official Wolfram team and opening issues: both existing bugs and enhancements highlighted by test use cases.
In the short term, we plan to release wolframite-1.0.0-alpha very soon so that the next stage of development can benefit from community feedback. This should happen as soon as we finalize some “getting-started” materials. These will be aimed at two target groups: Clojure developers interested in data science, and Mathematica / Wolfram users who would benefit from using the algorithms from Clojure (a real programming language!).
Permalink

 Coffee and breakfast on day 2
Coffee and breakfast on day 2 The screen printing caravan
The screen printing caravan Theater seating at Het Depot
Theater seating at Het Depot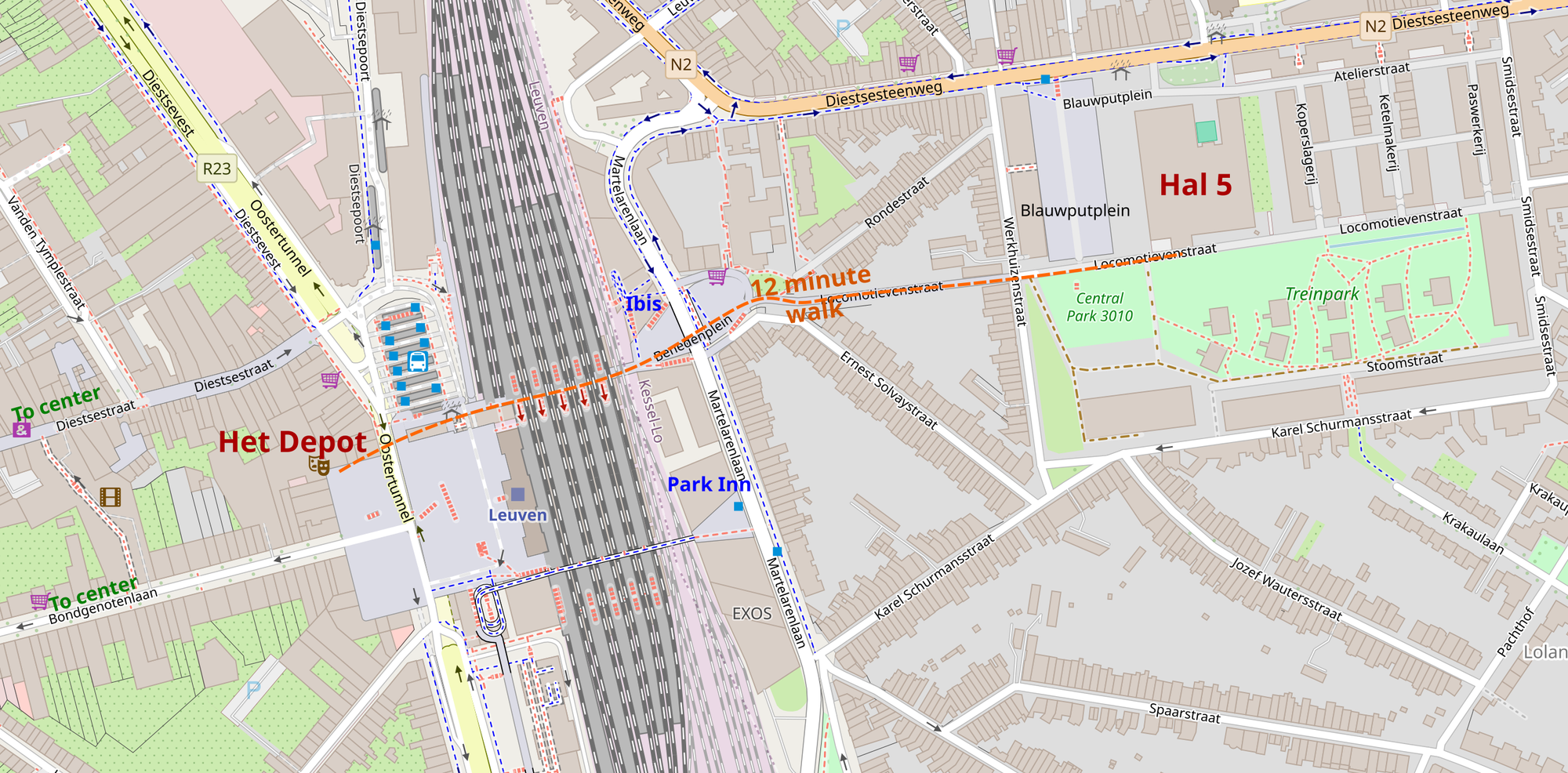 Map of the Leuven train station area
Map of the Leuven train station area





{kind=link}
{kind=link}